AWS vs GCP - GPU Availability V1
# September 21, 2022
There's an updated (and more accurate) comparison here: AWS vs GCP - GPU Availability V2
Cloud compute is usually seen as an ethereal resource. You launch VMs and spin them down, billed to the second. The billing and the mental model make it seem like these resources are limitless. That's typically one of the selling points versus on-prem compute. They can scale responsively to your load so you're not paying for excess compute that you don't need but it's there when you want it.
Of course, in reality they're not limitless. Cloud compute is backed by physical servers. And with the chip shortage of CPUs and GPUs those resources are more limited than ever. This is particularly true for GPUs, which are uniquely squeezed by COVID shutdowns, POW mining, and growing deep learning models. This can lead to resource availability issues when you need to spin up boxes on-demand, like for training and heavy inference load. And resource availability constraints mean you can't count on them being around when you need them.
After encountering some reliability issues with on-demand provisioning of GPU resources on Google Cloud, I put together a benchmarking harness to test AWS vs. GCP availability. It spins up GPUs at random times of the day to account for on-demand usage with unknown forecasts. We also expect that GCP and AWS will have different loads throughout the day as customers are doing different intensive jobs.
In total it scaled up about 3,000 T4 GPUs per platform over the course of two weeks. The y axis here measures duration that it took to successfully spin up the box, where negative results were requests that timed out after 200 seconds. The results are pretty staggering
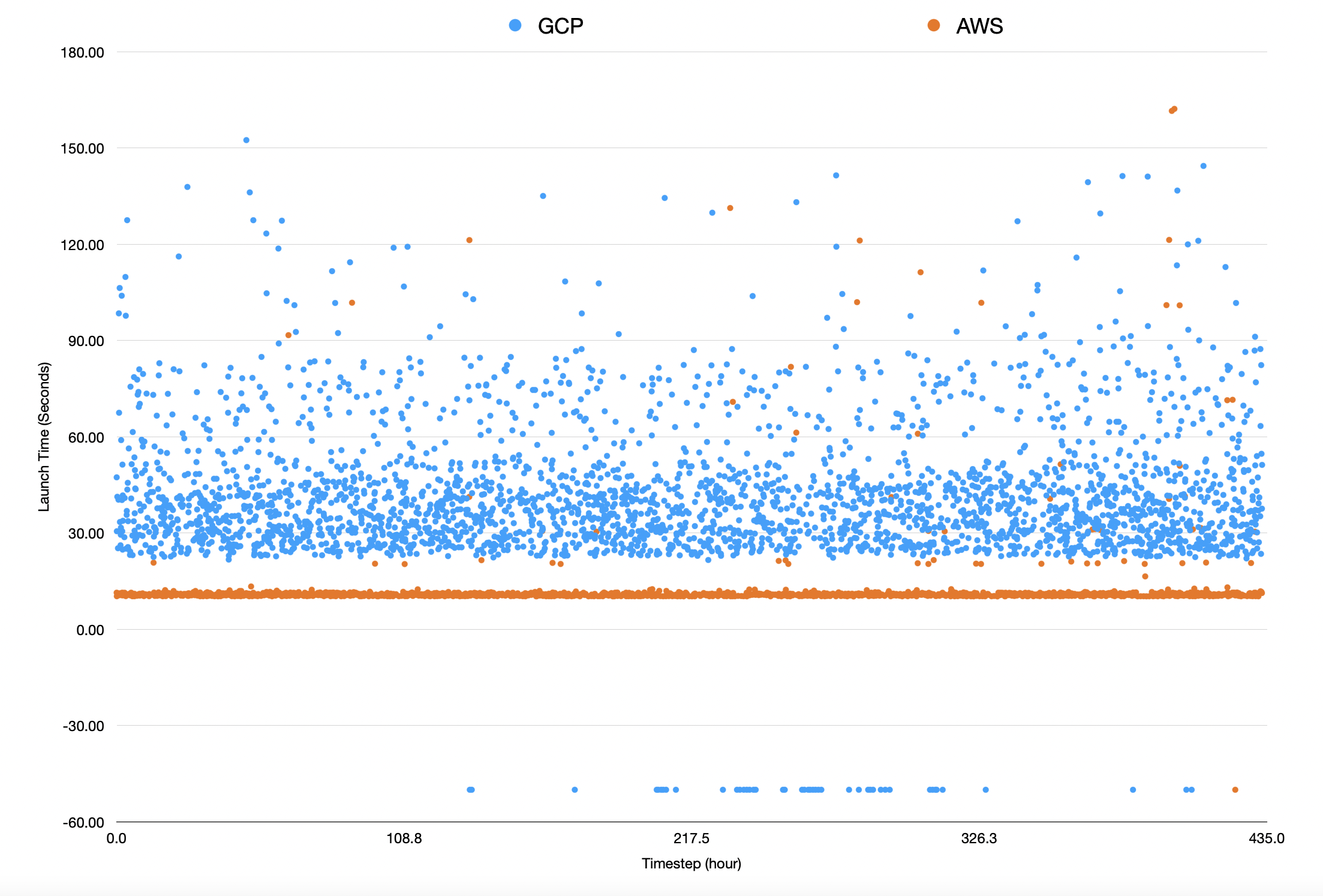
AWS consistently spawned a new GPU in under 15 seconds (average of 11.4s). GCP on the other hand took closer to 45 seconds (average of 42.6s). AWS encountered one valid launch error in these two weeks whereas GCP had 84. Some caveats are below, but the takeaway was:
AWS beat GCP in launch time by 66% and by errors by 84x.
These differences are so extreme they made me double check the process. Are the "states" of completion different between the two clouds? Is an AWS "Ready" premature compared to GCP? It anecdotally appears not; I was able to ssh into an instance right after AWS became ready, and it took as long as GCP indicated before I was able to login to one of theirs. You'll also notice there are some instances where AWS takes longer to spawn; they're just few and far between the fast launches. This also gives some support to the experimental procedure.
The offerings between the two cloud vendors are also not the same, which might relate to their differing response times. GCP allows you to attach a GPU to an arbitrary VM as a hardware accelerator - you can separately configure quantity of the CPUs as needed. AWS only provisions defined VMs that have GPUs attached - the g4dn.x series of hardware here. Each of these instances are fixed in their CPU allocation, so if you want one particular varietal of GPU you are stuck with the associated CPU configuration.
Quantile breakdowns of response times, when they succeeded -
| GCP | (GCP Support) | AWS | (AWS Support) | |
|---|---|---|---|---|
| Mean | 42.66 | 3103 | 11.44 | 3485 |
| 25% Quantile | 29.86 | 2264 | 10.38 | 2613 |
| 50% Quantile | 37.76 | 1510 | 10.68 | 1742 |
| 75% Quantile | 47.56 | 755 | 11.09 | 871 |
| 90% Quantile | 70.38 | 302 | 11.33 | 349 |
| 99% Quantile | 111.8 | 31 | 30.44 | 35 |
These error codes broke down as follows -
GCP (84 total)
- 74x - 409 Conflict
- 5x Operation timeout, GPU not available in 200 seconds
AWS (1 total)
- 1x - Instance did not reach break condition
A note on 409 Conflicts: This one was a weird error. It doesn't usually indicate capacity issues (ie. GCP did not report being out of GPUs) but there wasn't another good explanation. The error coming back from the API was vague about a conflict, but requests were spawned with unique identifiers based on clock time. So there shouldn't have been a conflict, especially not on the order of magnitude that was experienced here.
Even disregarding 409 errors, GCP fails to create GPUs more frequently - and has a higher spin up time across the board when they do succeed. Assuming you need on-demand boxes to succeed right when you need them, the consensus seems to clearly point to AWS. If you can stand to wait or be redundant to spawn failures, maybe Google's hardware acceleration customizability can win the day.
The entire testing harness is open source and I encourage you to run your own analysis - on different GPU configurations, spot instances, etc.