AWS vs GCP - GPU Availability V2
# November 14, 2022

When I compared AWS vs GCP GPUs in September it ended up generating quite a conversation on HN and Github. To briefly recap the context there:
- I needed dynamic GPU allocation for spiky data processing jobs with near-realtime user latency guarantees
- Availability (ie. will a GPU spawn) and cold-start launch (ie. how long it takes) are the two most pivotal KPIs
- Attempt to quantify how often GPUs are fully unavailable, since I ran into some anecdotal instances where GPUs wouldn't boot for 30mins on end
After publishing that post I ended up working with an assortment of Google engineers to see what was going on. Here are some learnings and a re-run of the previous experiment. For completeness I'll cover the full list in case you are struggling with some unexpected GPU allocation issues in production.
409 Conflicts
The lion's share of unresolvable errors during the first trial were 409 errors. These indicated that there was some resource conflict but they didn't give more specific details on what was in conflict. I suspected these weren't due to GPU availability but they did prevent the script from getting an accurate read on instance health (and I encountered a few at production time as well) so I kept these included in the result stats.
These errors ended up being a red herring. The GCP API returns 409 errors when you attempt an action on a resource that can't be fulfilled. In the experiment harness some of these requests were trying to shut down a box that already was in the process of terminating - hence the 409 errors. There can be a race condition here if boxes are shutting down independently and you re-issue the shutdown command.
My takeaway: ignore 409 codes if they occur on a termination action. Check manually for instance lifecycle (or receive a callback) if you are controlling your cluster programmatically.
Bin Packing
When scheduling VM jobs, Google uses some heuristics to determine which hardware resources to assign to each underlying request. These heuristics also affect how quickly assignment happens and therefore affect boot times. It seems like this shouldn't affect whether you eventually have a box allocated at all, but your mileage might vary here.
GCP couldn't disclose exactly what these heuristics are but they are minimally a function of the requested hardware. Larger VMs (measured in quantity of vCPUs) get preference. So even if you don't need many VMs to power your hardware accelerator you may want to consider requesting more for bin packing priority.
AWS on the other hand requires relatively large standard CPU configurations to get access to a GPU box. The new testing harness brings Google's dynamic vCPU request in sync with the one previously used for AWS.
Exponential backoff
The GCP client has a bug (or at least in this context a bug) where it exponentially backoffs when waiting for a box to finish spawning. Since spawn times are always in the double digits, a backoff here could double the time from 20s to 40s or beyond. There's an internal bug to fix this but for the time-being the patch looks something like this:
operation = self.instance_client.insert(request=create_request)
wait_func = partial(compute_v1.ZoneOperationsClient().wait, operation=operation.name, zone=request.geography, project=self.project_id)
operation._refresh = wait_func
operation.result(timeout=self.create_timeout)
The zone operations client will launch a pager that greedily blocks for the operation to complete.
Region support
A Github comment raised a fair point that my AWS testing script launches into a region with multiple availability zones, whereas the GCP script launches into a single availability zone. AWS therefore has more degrees of freedom here to spawn into whatever availability zone has active resources whereas GCP is capped at the physical constraints of what is in this one zone. They recommended I round-robin spawn into different availability zones.
After thinking on this for a bit, I think the initial choice is correct. The API layer of abstraction for instance spawning is different based on cloud provider. Amazon lets you say "I'm agnostic to the availability zone, just get me the resource." It can figure out the load balancing on your behalf 1. GCP has no similar endpoint and requires client to pre-select the region, without the external context of which zones have availability. The test harness is therefore reproducing the behavior of a UI or programatic client caller. To spawn an instance somewhere we must pick a zone apriori.
On my wishlist is either:
- More transparency about the zones with resource availability, covering spot instances and on-demand provisioning. Clients could then pick a region with high current capacity to have a higher probability of spawn success. Most GPU is compute bound instead of network bound so GPUs generally don't need to be colocated with the other service hardware.
- I imagine the above might reveal too much of the plumbing behind the scenes. As a fallback, a new more generic API layer to handle region-based spawning and internal load balancing.
Outlier issues
This continuous test also uncovered some other internal bugs that were resulting in higher than average allocation times, namely in the 95% percentile of load times. There's a pretty tight band on the 0-99% of requests for both AWS and GCP. The extreme cases are outliers (GCP: 26, AWS: 29 of over 2500) but themselves sit at 80s+ and therefore push up the overall mean.
Some of these issues could be fixed and some were apparently transient. I don't have much more context on the specifics here. But my main takeaway is if you see some unexpected errors on GCP, report them sooner rather than later. Logs eventually decrease in fidelity over time. Coupled with a timestamp and an observation they're able to do much deeper digging.
Results
With the above items addressed and benchmarking running for two weeks in late October and November, we end up with:
GCP (4 total)
- 3x: Operation timeout, GPU not available in 200 seconds
- 1x: 503 Service Unavailable
AWS (0 total)
- No spawn issues
In sum: AWS averages a 7.37s spawn time and GCP averages a 29.18s spawn time. 4 GPU availability issues were encountered in 15 days of running trials on GCP and 0 were recorded on AWS.
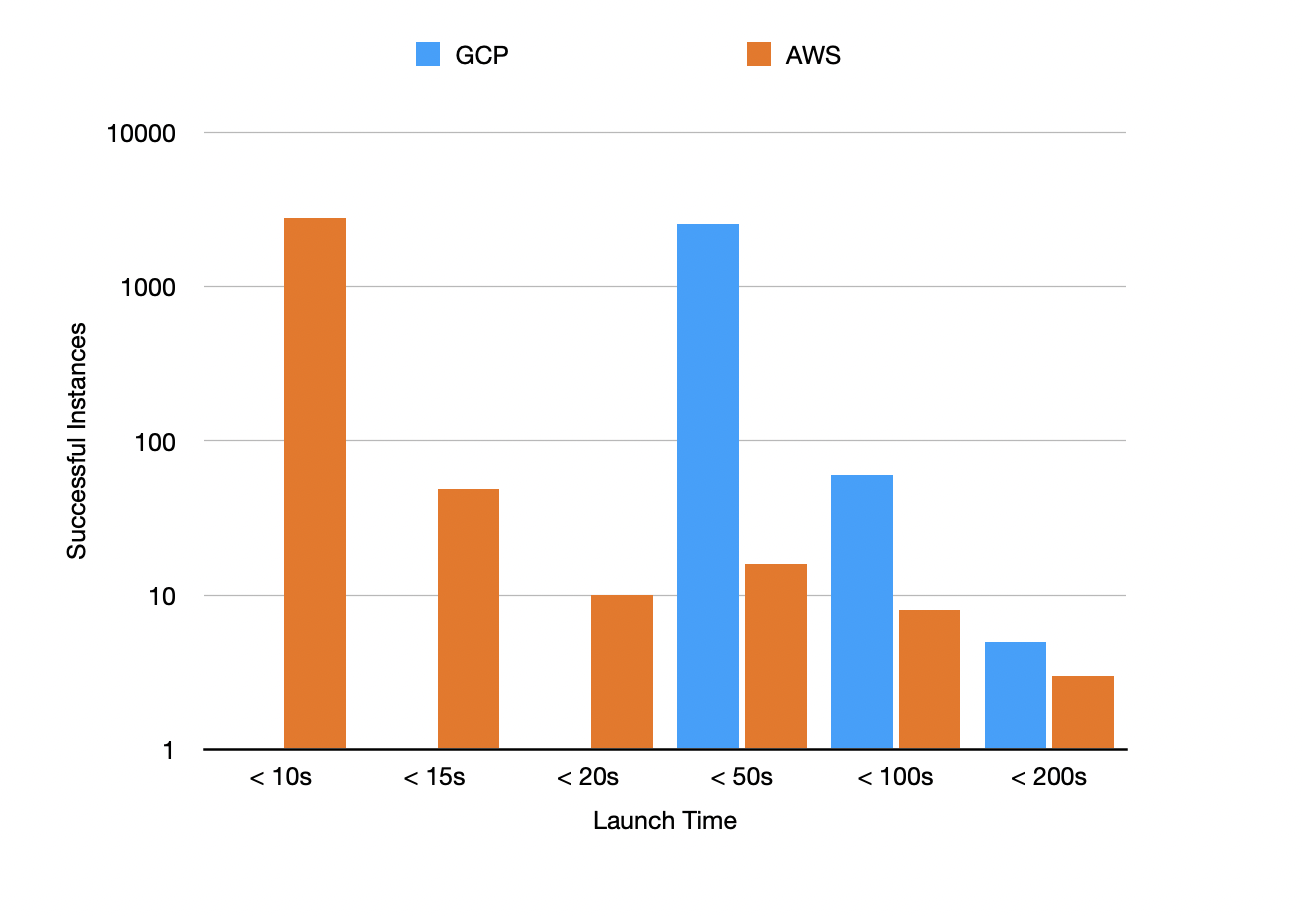
Launch times break down as follows. AWS leads the pack here with the quickest time to launch at below 10s for the majority of cases while GCP is below 40s. Both have their extrema but the overall mass of AWS skews lower.
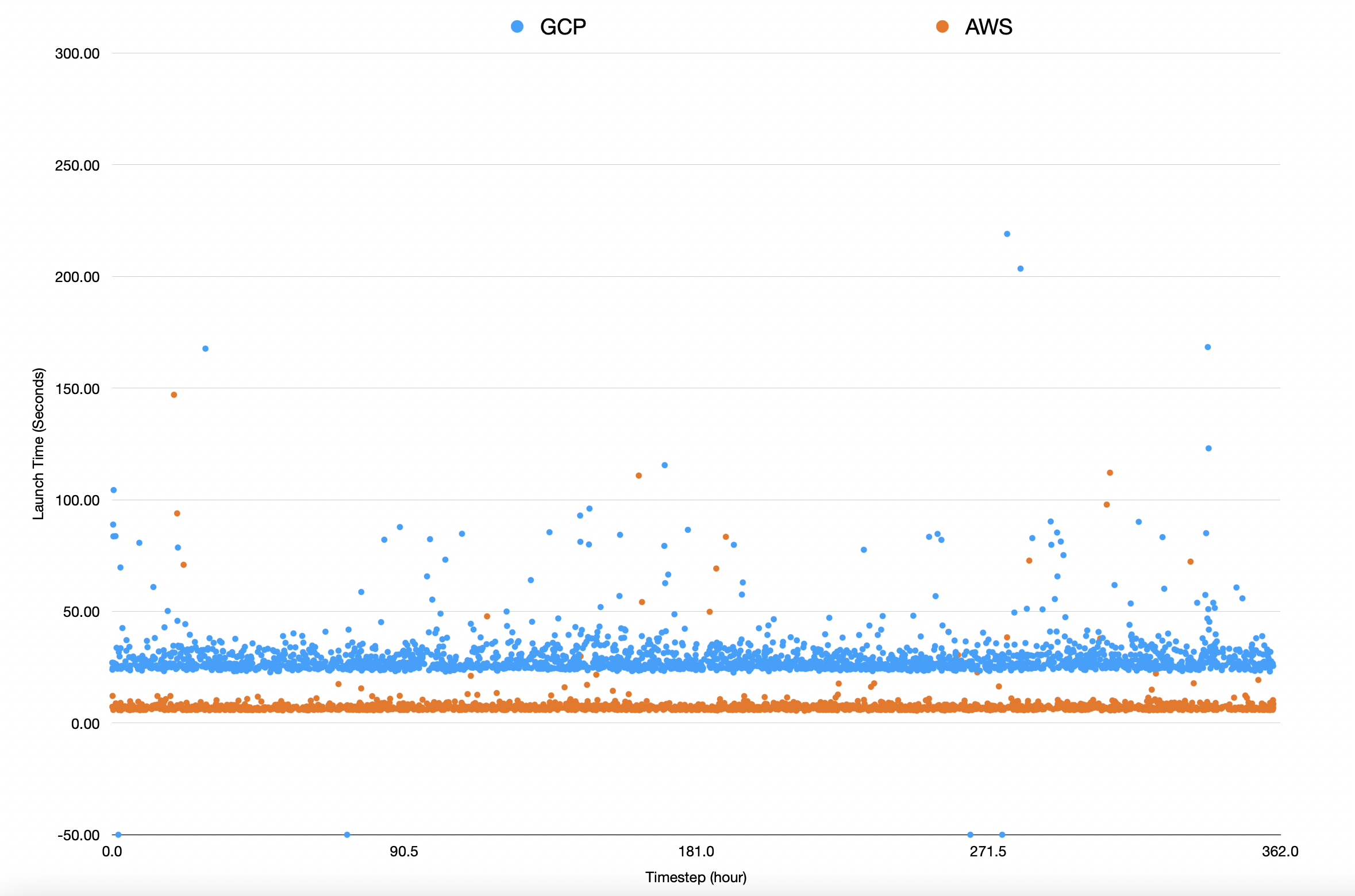
The GCP failures occurred at 1:48pm, 12:42pm, 1:49pm, and 9:40pm on different days (EST). The 1:48pm failure seems a bit suspect, as if there is a batch processing job that's gaining the majority of us-central1-b availability. These failing datapoints are the ones that are set arbitrarily at the -50 y-axis.
The specific numerical breakdowns:
| GCP | (GCP Support) | AWS | (AWS Support) | |
|---|---|---|---|---|
| Mean | 29.18 | 2603 | 7.37 | 2885 |
| 25% Quantile | 24.96 | 1949 | 6.2 | 2164 |
| 50% Quantile | 26.51 | 1300 | 6.7 | 1443 |
| 75% Quantile | 29.83 | 650 | 7.19 | 722 |
| 90% Quantile | 34.49 | 260 | 8.16 | 289 |
| 99% Quantile | 82.1 | 26 | 17.79 | 29 |
Takeaway
I was very impressed with the diligence that the GCP team paid to my initial report. They filed fixes for some of the above issues and were able to speak pretty openly about strategies to improve the situation. The future of their hardware accelerator development looks to be in good hands.
Like I mentioned in my original thread, exactly what defines reliability here is largely context dependent. If near-guaranteed availability and launch times for minimal latency are the name of the game, AWS still looks like a safer bet. This was the case in my original spec. If customizable VM configurations are at play, GCP is worth benchmarking with your unique situation. There seems to be more variance there on exact request parameters and geographic region.
And of course, if you want to run your own trials or extend the test cases, give a visit to the Github repo.
Full disclosure: GCP ended up refunding me for this experiment which was much appreciated. I paid out-of-pocket for AWS for both trials. Many thanks to Adam, Adrian, Karen, and Simon from the GCP team for their help troubleshooting.
-
To be clear, AWS makes no guarantees about how region spawning will function when requested. But intelligent balancing is on the table because of the abstraction layer provided. ↢