Constraining LLM Outputs
# February 20, 2024
LLMs are by definition probabilistic; for each new input, they sample from a new distribution. Even the best prompt or finetuning will minimize (but not fully resolve) the chance that they give you output you don't expect. This is unlike a traditional application API, where the surface area is known and the fields have a guaranteed structure.
To use LLMs in any kind of downstream pipeline, you need to get them closer to this API world. You need to be able to enforce a standard API contract of the data you want. Requesting JSON output is the common way to do this - but even with the best prompts, often at least 5-10% of outputs are subtly invalid (missing commas, extra quotes, etc). Constrained generation is a way to constrain your model to only produce valid JSON.
Technically - you can force any model to give you valid JSON. But the quality of this JSON will vary depending on model and configuration. Let's look into whether finetuning a model to produce JSON is preferable to forcing JSON on a non-finetuned model.
Constrained Generation
You can force any transformer to generate a standards compliant schema. Since most generative models are auto-regressive, the output of one step becomes the input to the next step. Schema generation works by postprocessing these output logits to require tokens that we know must exist in that location.
JSON Schemas are a great format to specify this structure. Their spec gives you wide latitude in specifying expected constraints (length, enum values, nested objects). These allowable values then become your probability/logit masks.
Consider this JSON schema pseudocode:
{
age: 1-150,
emotion: "happy" | "pensive" | "busy",
bio: "[freetext]"
}
At timestep 0, the model should only output { to conform to the schema. After this, it should only output age:. After that, it can produce any number so long as it's between 1 and 150. So on and so-forth, we can build up a JSON payload that is guaranteed to be valid.
There are a few different approaches to actually implement this behavior:
- Build a state machine that validates a context-free grammar, where the logits become the allowable transitions from state to state (seen in outlines)
- Build up the payload key-by-key, giving each key particular validation and stopping criteria (seen in jsonformer)
Either way, you end up with a compliant JSON representation. But this still leaves which model architectures and prompts you should use in this generation.
The Experiment
I used web_nlg.v2.1 as the original dataset. Each datapoint is a collection of RDF triplets and a human authored summary that combines these triplets into natural language. A sample:
{
"category": "Airport",
"mtriple_set": {
"mtriple_set": [ [ "Aarhus_Airport | location | Tirstrup" ] ]
},
"lex": {
"lid": [ "Id1", "Id2" ],
"text": [ "Aarhus Airport is located in Tirstrup.", "The location of Aarhus Airport is Tirstrup." ]
}
}
{
"category": "Artist",
"mtriple_set": {
"mtriple_set": [ [ "Paraguay | language | Spanish_language" ] ]
},
"lex": {
"lid": [ "Id1", "Id2" ],
"text": [ "The language is Paraguay is Spanish.", "Paraguay is where the Spanish language is spoken." ]
}
}
The original task definition was to convert a sequence of RDF triplets to text, but we can flip that here to generate RDF JSON triplets from the text itself. Its structure has the benefit of guaranteeing somewhat unique JSON payloads. Since the RDF triplets have different relationships and subject types, we can ensure that not every JSON output is going to be the same key/value pairs.
We fully split the dataset based on the category type, to avoid learning nuances in extracting particular relationship types. To the best of our ability we aim for net new JSON payloads that showcase its generalization at test time.
We convert these RDF triplets into the following JSON format:
Input: choice(rdf["text"])
Output: {
rdf["src_type"]: rdf["src"],
rdf["relationship"]: rdf["dst"]
}
Since each text passage can have multiple RDF triplets tied to it, we need some way to indicate to the model which entity relationship we want to extract. We look up the DBpedia ontology for each source entity and use these as the keys. This provides relatively generic but directionally helpful categories for the different RDF sources: place, infrastructure, person, mean of transportation etc.
SELECT ?type WHERE {{
<http://dbpedia.org/resource/{src_object}> rdf:type ?type .
FILTER(STRSTARTS(STR(?type), "http://dbpedia.org/ontology/"))
}}
LIMIT 1
Combining these two data sources will result in a final datapoint that looks like the following. It's this extraction that we want to perform at inference time.
Input: Located in Alcobendas, Adolfo Suárez Madrid–Barajas Airport
has a runway length of 3500 metres and a runway named 18R/36L.
Output: {
"infrastructure": "Suárez Madrid-Barajas Airport",
"location": "Alcobendas"
}
Models
We're going to try the following models:
JSON-Finetuned: A Mistral-7B finetuned on the JSON payloads. This represents the clearest alignment of the model contract at training and inference. Its training data looks like:
> prompt_json = (
f"""Given the following text description, extract the main entity
relationships into the following JSON schema.
TEXT: {text}
JSON: {json}
"""
)
Given the following text description, extract the main entity
relationships into the following JSON schema.
TEXT: The Aarhus is the airport of Aarhus, Denmark.
JSON: {"infrastructure": "", "cityServed": ""}
> goal_json
{"infrastructure": "Aarhus Airport", "cityServed": "Aarhus, Denmark"}
Plaintext-Finetuned: A Mistral-7B finetuned on plaintext data. Our goal here is to expose the model to the same core knowledge as the JSON-finetuned model, but not actually in the expected format. We use a template to convert our json output into plaintext output. Its training data looks like:
> prompt_plaintext = (
f"""Given the following text description, identify the requested
relationships involved.
TEXT: {text}
SRC: {src_key}
DST: {dst_key}
"""
)
Given the following text description, identify the requested
relationships involved.
TEXT: The Aarhus is the airport of Aarhus, Denmark.
SRC: infrastructure
DST: cityServed
> goal_plaintext = f"The {src_type} {goal_src} has a {rdf_words} of {goal_dst}"
The infrastructure Aarhus Airport has a city served of Aarhus, Denmark
Mistral-7B-Instruct-2: A baseline model, not finetuned on our dataset. Sets a good threshold for what a good quality instruction following model is able to achieve. We assume it has seen a fair amount of JSON pairs in its pretraining or alignment datasets.
Finetuning
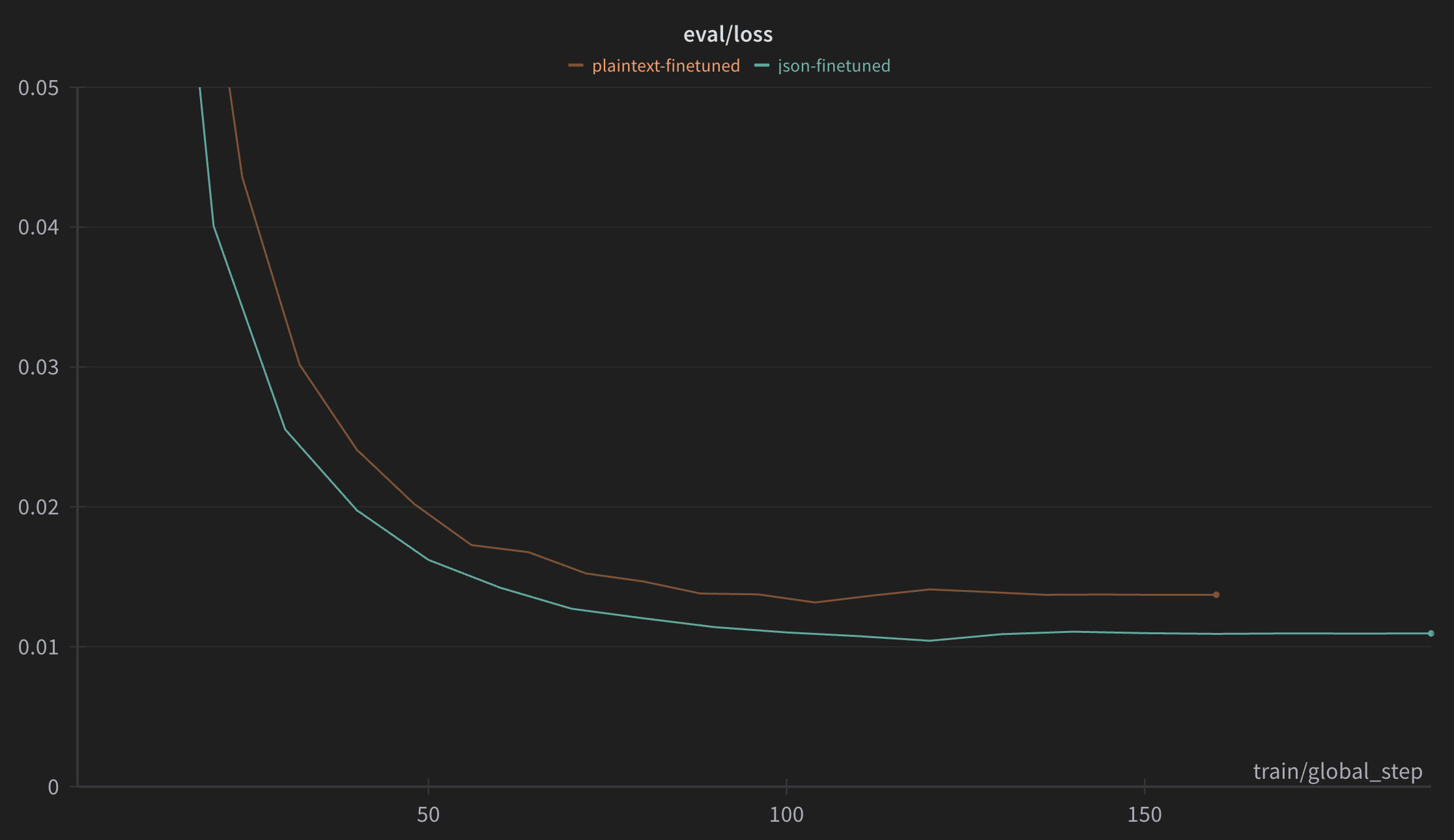
The perplexity / evaluation loss of the plaintext finetuned model remains higher than the JSON model, despite being exposed to the same training set.
We can blame this on the format of JSON.1
Since JSON doesn't tokenize very cleanly, it takes more tokens to generate the JSON schema than to generate our plaintext template. Consider the above example:
{"infrastructure": "Aarhus Airport", "cityServed": "Aarhus, Denmark"}
With the tiktoken BPE tokenizer, this results in the following tokens. I've added labels for the ones that come from the JSON schema.
{" - JSON
inf - JSON
rastructure - JSON
": - JSON
" - JSON
A - Var
arhus - Var
Airport - Var
", - JSON
" - JSON
city - JSON
S - JSON
erved - JSON
": - JSON
" - JSON
A - Var
arhus - Var
, - Var
Denmark - Var
"} - JSON
There are 13 JSON and 7 Var tokens. That's 65% of the overall token mass (and therefore loss) that's just dedicated to encoding the JSON format. Furthermore, these tokens are always deterministic given the specification in the input prompt.
We reason that once the model learns the core JSON mapping of input to output, the loss shoots down. The incremental gains from this point onward represent the actual learning of the content once the pattern has been established.
Evaluation
To evaluate we pass these two finetuned models through a JSON-constraint framework. We prompt each model with a prompt that includes the expected JSON-schema and one that doesn't include the JSON-schema, so the model only relies on the keys injected into the autoregressive output2.
Since the RDF triplets are in plaintext, there are a host of evaluation metrics that we could use to compare our predicted outputs (levenshtein distance, BOW Precision/Recall, etc). To keep things simple and interpretable, we benchmark all models on accuracy. This answers whether the model is able to recover its groundtruth exactly.
| Model | Prompt includes schema | Prompt excludes schema |
|---|---|---|
| Mistral-Instruct-V2 | 46.35 | 50.20 |
| Plaintext-Finetune | 73.30 | 72.35 |
| JSON-Finetune | 80.00 | 79.45 |
Perhaps no surprise, the JSON-Finetune performs better than the other models. Diving into the results a bit deeper, the Plaintext-Finetune often makes the mistake of including too much context in the JSON window. This is likely biased by the initial finetuning that encouraged one string to contain all content. Looking at a few results:
text: The AC Hotel Bella Sky in Copenhagen is part of Marriott International. Marriott International was founded in Washington DC and a key member of staff is Bill Marriott.
goal: {'company': 'Marriott International', 'foundationPlace': 'Washington, D.C.'}
prediction: {'company': 'Marriott International', 'foundationPlace': 'Washington, D.C.} The constraint model has a company of Marriott International'}
Often these results appear very close to generating valid JSON, but forget a valid closing tag and therefore continue past the end of where it should.
text: Julia Morgan, the architect, was born in San Francisco and some of her significant projects include Asilomar Conference Grounds, The Riverside Art Museum, Hearst Castle and Asilomar State Beach.
goal: {"person": "Julia Morgan", "birthPlace": "San Francisco"}
prediction: {'person': 'Julia Morgan, architect, has a birth place of San Francisco} The person Julia Morgan has a birth place of San', 'birthPlace': 'San Francisco'}
Sometimes the answers are just wrong when compared to json predictions, but these are in the minority of cases.
text: Abradab performs hip hop music which originated in Disco and its stylistic originated in Jazz.
goal: {'person': 'Abradab', 'genre': 'Hip hop music'}
prediction: {'person': 'Hip hop music', 'genre': 'Disco music'}
These errors are similar whether we included the initial JSON schema in the model or not. So as an additional experiment, I included a few-shot examples into the prompt to bias the model to writing shorter responses:
{Original Prompt}
Output Examples:
1. {"airport": "Aarhus Airport", "cityServed": "Aarhus, Denmark"}
2. {"meanoftransportation": "ALCO RS-3", "cylinderCount": "12"}
3. {"athlete": "Alex Tyus", "club": "Maccabi Tel Aviv B.C."}
This resulted in a new set of finetuned executions.
| Model | Prompt includes schema | Prompt excludes schema |
|---|---|---|
| Mistral-Instruct-V2 | 46.35 | 50.20 |
| Plaintext-Finetune | 73.30 | 72.35 |
| Plaintext-Finetune (Few-Shot) | 68.05 | 68.55 |
| JSON-Finetune | 80.00 | 79.45 |
Interestingly, it does worse than the baseline plaintext-finetune. It potentially is biasing the output just for the subjects included in the few shot examples. With enough input examples it's likely possible to close the gap further, but it's a good cautionary tale that finetuned models are inclined to output in exactly the format they are trained in.3
Conclusion
Even though you can force a JSON schema on every model, the model itself won't be internally aware of the constraints that you impose during logit postprocessing. It's not taking into account additional signals about desired output - we're just artificially forcing the outputs to conform to a valid JSON schema.
It's therefore not a particular surprise that the JSON model exceeds the other options, since its internal behavior most closely aligns with the postprocessing constraints. And it's worth noting that results might be a little different if we were classifying enum values (very constrained) versus the freeform text that we saw here. If you have some thoughts on datasets that are amenable to testing this hypothesis, drop me a line.
These JSON constraints are useful to make sure the model is generating data that can be validated, versus a way to convert all models into high quality output machines. My default approach going forward is to ensure all pseudo-structured training data is properly formatted as JSON, to help squeeze out the additional performance at runtime.4
-
I'm always hesitant to give a human explanation for model convergence behavior but here we go. ↢
-
I tried both
outlinesandjsonformerto do this prediction. Outlines showed more variable inference timing - it was faster on the JSON-finetuned model and much slower (3x-4x) with the non-JSON-finetuned model. This is unintuitive, since the constraints on token length are the same across both values. Even if the values are bad, the finite state machine should guarantee that we are only running the generation loop a max ofmax_tokenstimes. I did a quick investigation into this and believe it's due to additional loops that are avoided by a model that's already biased to output JSON and fulfill the FSM. The authors are taking a look. ↢ -
Training on a diverse dataset with many different system prompts and expected outputs is a good way to keep the generality, but for finetuning on one system task you're somewhat constrainted. ↢
-
I mean performance here in the metrics sense. But constrained generation also can end up being faster, since you can fast-forward over tokens that you know must be generated. ↢