Scoping an ML feature
# April 26, 2021
This article came out of a presentation that I gave to our Product organization around defining and building ML features. I try to unpack the questions that a product team should consider as they’re looking to understand where machine learning can supercharge their user journey and where it might fall flat.
Business leadership, product managers, and researchers too often speak different languages when talking about machine learning.
I’ve been lucky enough to spend the last four years at the intersection of product development and machine learning. I’ve run both product teams and machine learning research groups. I’ve also advised business leadership on corporate strategy around adopting useful machine learning systems. I’ve seen these different perspectives firsthand while helping to bridge the worlds.
Most confusion when building ML features comes at the beginning of a project. The goals are vague, the data isn’t in the expected format, or the metrics are ill-defined. This is a key place for product managers to articulate user needs in a way that machine learning researchers can translate into a well-defined research problem. Today we’ll look at building robust product scopes that your team can jump into executing.
Get agreement on user impact
Stakeholders look at ML differently. The marketing organization might want to ride the latest press wave around robotic automation. Engineering might see it as an opportunity for new technology stacks. Corporate leadership might want it to meet investor expectations.
These influences are often strong. But don’t use them as reasons to prioritize. Instead, prioritize what is going to positively affect the user’s experience in your product. This rallying cry allows different members of the organization to agree on project prioritization when it comes to ML.
A good feature must benefit users. Good product design stems from an empathy for users and understanding their needs. Machine learning is simply a tool in your toolbox to realize that benefit.
Unless you’re working with a theoretical AI research group like Deepmind, Facebook Research, or Google AI, encourage machine learning engineers to speak in these terms as well. What product feature is their research endeavor going to move the needle on? How do users benefit?
I look at intelligent features under three main lenses.
Save Time
What takes a lot of time for users today? Where do you require users to enter content in your platform? Is there a way to automate the input or portions of it? One of the most common ways to streamline input is showing suggestions instead of asking users to write content from scratch.
In Gmail, the time investment is composing new email messages. This led Google to develop suggestive sentence completion. If you start writing a sentence that is commonly ended in a certain way, Gmail will recommend that ending. Hit tab and it will complete it for you.
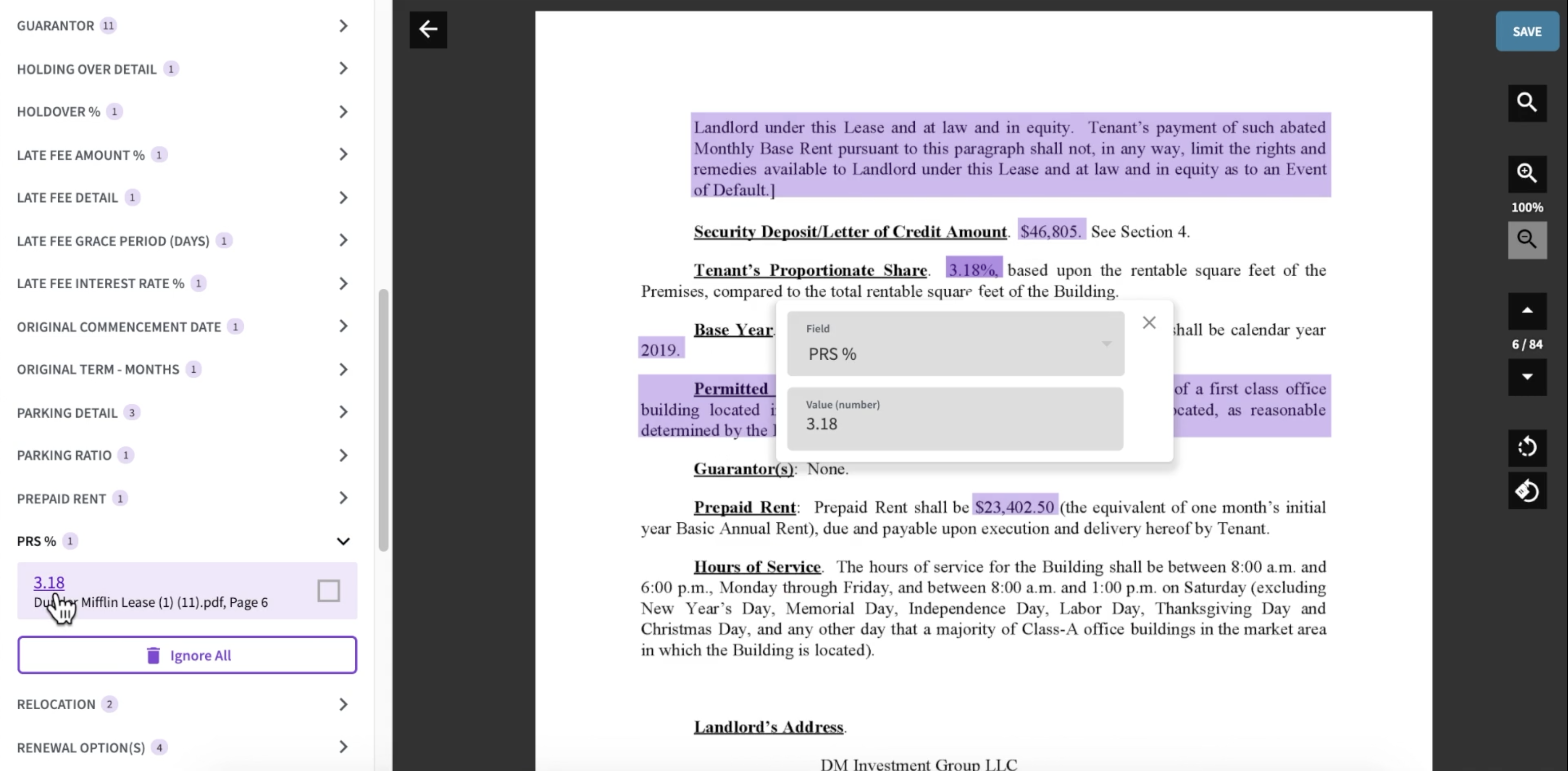
In AbstractCRE (a company in which I’m an investor), the time investment is manually reading property leases and extracting the business metrics: cashflow, square footage, etc. This led them to develop suggestive highlights. They predict candidates for these business metrics and ask analysts to confirm suggestions instead of searching through the entire document.
These approaches save time and money for users, especially when repeated over hundreds or thousands of interactions.
Find the Signal in the Noise
Does your software have a lot of content that is difficult to analyze one-by-one? Does it require reading paragraphs to gain an overall impression? Searching through thousands of photos? ML can surface themes or pinpoint what users are looking for much quicker than they could do on their own.
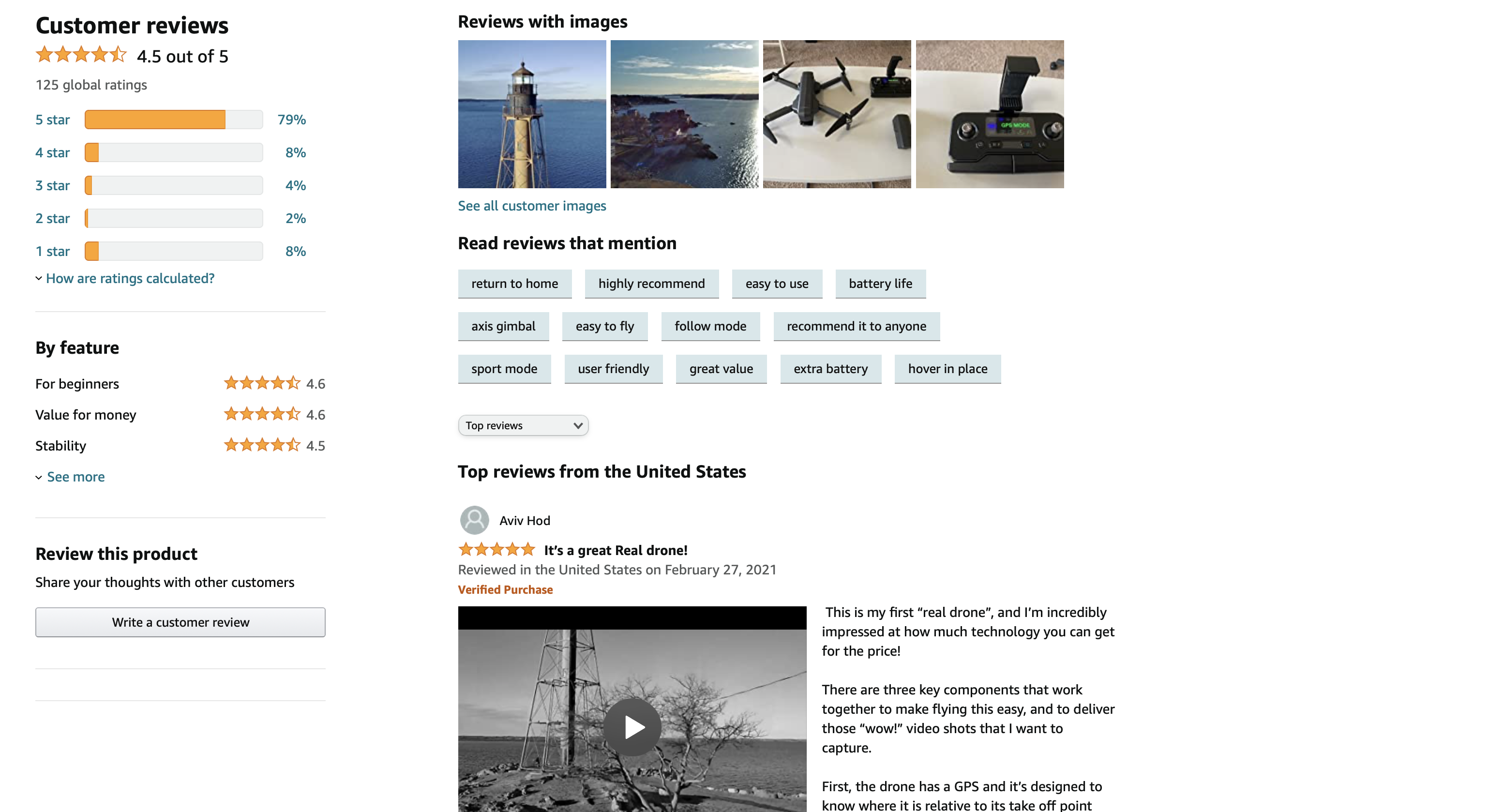
On Amazon, some products have thousands of reviews that go into rich detail about their experiences. Users struggled to find the primary decision making criteria when evaluating a new purchase. Amazon solved for this need by rating the sentiment of each of these posts as positive or negative, and grouping them by the topic that they discuss. Instead of wading through reviews and losing context, users get a sense of the main themes that are echoed throughout multiple reviews.
In Apple Photos, users often tried to find a memory that’s buried in tens of thousands of past photographs. People usually remember what a photo is about but not exactly when it was taken. In response Apple recently rolled out a search bar where you can describe the contents of a photograph and get back matching results. Try searches for “Christmas Tree,” “Vacation,” or “Sunset” within your photo album.
These approaches allow users to more easily find signal in the noise.
Make a Better Decision
Do users have difficulty making a decision? Do they get stuck at one place in the user journey? What information are they missing to make the right call? Intelligent systems can predict or quantify information that humans would have trouble identifying by themselves.
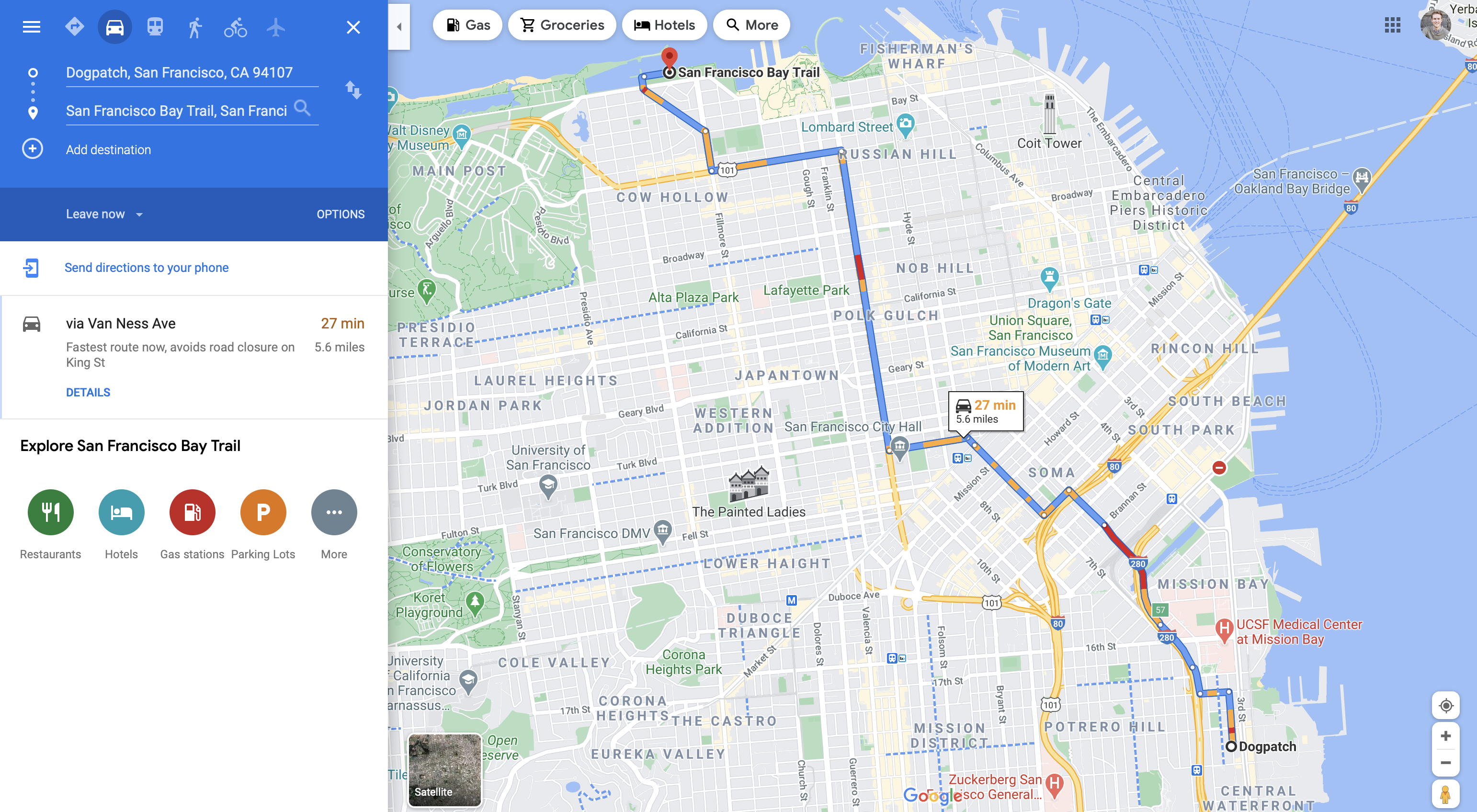
On Google Maps, users would get a few different route suggestions with an estimated time of travel. However, this time was static to the route and wouldn’t consider rush hour or a recent accident. Google addressed this by recording traffic patterns and training a model that predicts how this traffic will change throughout your trip. It frees users from having to think about how conditions are going to change once they decide on a route.
At Globality, where I work, we provide a marketplace where business users can purchase high value services in marketing, consulting, legal, IT, and HR. This is typically the role of a procurement organization and users often get stuck when trying to make a decision between multiple vendors. The platform helps them make an evaluation between these companies by showcasing relevant past work experience, reviews of their colleagues, etc. The system’s point of view leads to much higher conversion in the decision-making journey.
These approaches propel a user forward in their journey towards the right answer for them.
Define the model contract
All machine learning can be thought of as a function, like the f(x)=y from high school algebra. You have some input and you expect some output. This mirrors the functions that are used in broader programming and computer science; except instead of an engineer filling out the function behavior it’s an optimization algorithm. This is known as the model — and the relationship between the input data and the output predictions form the model contract.
When doing the product work to scope an ML feature you need to be incredibly clear about what the expected input and output should look like. This dictates everything downstream: how to collect the data, how to do the data modeling, and how to benchmark success.
Are you going to accept text as input and predict sentiment? Pictures of an ultrasound report and report on whether there’s a tumor? Accept user profiles and estimate what products they’re going to buy? My barometer for a good model contract is whether a human can reach a good conclusion given the same input. Machine learning isn’t magic and trained humans are typically great pattern recognizers. We can read a passage and understand sentiment; a radiologist can read exams and build a report; I can read a user bio alongside their past purchases and predict the additional products they’ll buy.
Note that this contract does not include the algorithm that will actually solve the problem. That’s a good thing. The algorithm choice — whether unsupervised, supervised, or reinforcement learning — can be thought of as an implementation detail. Your machine learning partner will figure this out through the course of research.
Think about how humans do it, then break the contract down even further
Machine learning should only be used where you can clearly define the input and output contract of a system, but you can’t articulate how a machine can do that same thing.
Let’s take self driving cars as an example. When I’m driving my own car, I scan the road. I then tilt the wheel, push the gas, or tap the brake. Once you’ve been driving for a few months or years, it’s intuitive.
If we use that same framing as a machine learning contract: we get the scenery as input, and we output commands to the car’s steering controls. The machine learning model figures out how to do everything in-between.
That’s fine in theory but it suffers from a few problems in practice. Namely, how do we assess the performance of the system? It could work well on highways but not on city streets. It could work well in San Francisco but fail in Austin. I might decide to merge left while my passenger would have decided to merge right. It could overly torque the wheel in a certain situation, and under torque it in the rest. It’s impossible to say what the model is doing behind the curtain and therefore impossible to feel comfortable that it will correctly translate the complexity of the world into commands to the wheel.
Where possible, you should break down your problem to be more granular by thinking about how a human actually solves the problem. What do we actually do when we’re driving?
- Determine obstructions in our view, either in the road or cars that are traveling alongside us. Apply the accelerator and brake depending on the distance to cars in front of us.
- Look at the road for lane markers, either white or yellow. Stay within our lane by controlling the wheel and following the curve of the road. The color and thickness of the lines represent different allowable passing manuvers.
- Identify stop signs, speed limits, or traffic lights. We then adjust our speed or manuvers according to sign’s stated intent.
- Pray for a sunny day. California drivers are horrible once you add a light sprinkle of rain.
Now that we’re done with DMV 101, how does this translate to an ML system?
Each of these driving stages has two steps. On the first step you use your perception to get a sense of context. Then you map the context to a series of well-defined rules about how you should behave given what you’re seeing. Humans make this relationship implicitly but machines can do so explicitly. This is exactly what Waymo, Cruise, Tesla, and the others do with their own self-driving car systems. They have machine learning systems that predict the surroundings. Then a deterministic control system translates the context into the car’s navigation and physical motion. You’re leaving the perception to the machine learning but the action to the deterministic code.
Better model contracts lead to better benchmarking. Say your lane detection is working flawlessly but your obstacle detection needs work. This helps prioritize where you need further research and investment to improve these sub-models. This also makes the system more explainable, which is a big help in determining error modes and when it’s going to fail.
Break your machine learning model into the smallest problem you can. Otherwise you’re going to be surprised by some of the edge cases that will inevitably arise once you ship.
How do you create a virtuous cycle within the product experience?
You’ll likely have to spend time labeling data before you launch any ML feature. This work provides the examples of the input/output contract that you’ll need to train and benchmark your models. Once you launch you have the opportunity to outsource much of this data generation to your users.
The best machine learning systems fulfill the same model contract with user feedback as you would have with internal labeling. The more that users interact with the system, the more valid data you’ll collect, and the better the models will become. This forms a virtuous cycle within the product feature.
A generic way to create this feedback loop is to allow users to confirm or deny predictions. Spotify provides a thumb up or thumb down for every song that’s played on the radio. These ratings change the songs that are played later in the playlist. If the model is predicting songs, it’s reasonably confident that you’ll like them. A downvote is a strong signal to the model that it got the prediction wrong and therefore should change them for the future. An upvote might encourage it to lean further into that genre.
Another method is to flag incorrect results and then submit to the backoffice for further data labeling. In Tesla’s self-driving system, they record any situations where users are forced to intervene and take over the wheel. It records a 30 second clip of all sensors around the intervention; what led up to the problem, the error that the car made, and the human solution. This instance gets added to a queue, where Telsa employees label the surroundings and analyze the control system to determine why it made the error on the road. The system trains on these datapoints to hopefully make a better judgement in a similar future situation.
You should ground any explicit requests for feedback in what will deliver the best user experience today as well as in the future.
Will the system remember their feedback? Does it put it into use somehow? From what I’ve seen, users enjoy weighing in on machine predictions. There’s something magical about seeing a machine do a complicated task correctly and they’re relatively happy to correct it when it fails. But there has to be a guarantee that doing so immediately impacts their user experience in some way: playing a more relevant song next, providing a corrected grouping of photos, or blocking all spam addresses from this sender. If it’s exclusively used for vague future purposes, they’ll quickly lose their appetite for correcting it.
Closing
At this point, you have a good idea for your product feature and for the machine learning contract. You can make your models more explainable and create a virtuous cycle.
Bear in mind, you don’t need to bake this entire solution on day one. Product has equal partnership with machine learning researchers in sketching out both the feature and the research direction. It will be iterative; the model contract may change over time as you learn more. But a robust starting place based on subject matter expertise is critical in speeding up your research and development work.
In the second article we’ll look at defining metrics of success for your machine learning project.