Let's talk about Siri
# April 28, 2023
I was considering a quick weekend project to route Siri requests to ChatGPT. My immediate thought was pretty simple based on my existing mental model for Siri as a local<->server pipeline:
- Set up a MITM proxy or custom DNS server
- Intercept outgoing Siri requests and route them to a backend LLM
- Respond with a correctly formatted payload, potentially with some additional utilization of the widgets that are bundled in iOS for weather or calculated responses
That required me seriously poking around with Siri for the first time in a couple years. A lot has changed since I last took a look.
Everything's Local
Since iOS 15, all Siri processing is done locally on device. There's a local speech-to-text model, a local natural-language-understanding module, and a local text-to-speech model. The local NLU module surprised me the most. All logic appears hard-coded and baked into the current iOS version. It'll respond to known tasks like the weather, setting a timer, converting weight, looking up a word, and sending a text message. For all other requests it will open up a web view and search your default search engine for a result. It doesn't attempt to create a text response to queries that fall out of its known action space.
To confirm this behavior I set up a proxy server and started capturing requests. Making a Siri request did indeed issue no external requests, until you ask it for something that requires current world understanding. Asking What's the Weather? routes a specific weather request to Apple's SiriSearch backend through PegasusKit. PegasusKit is a private framework that contains some miscellaneous utilities for image search and server communication.
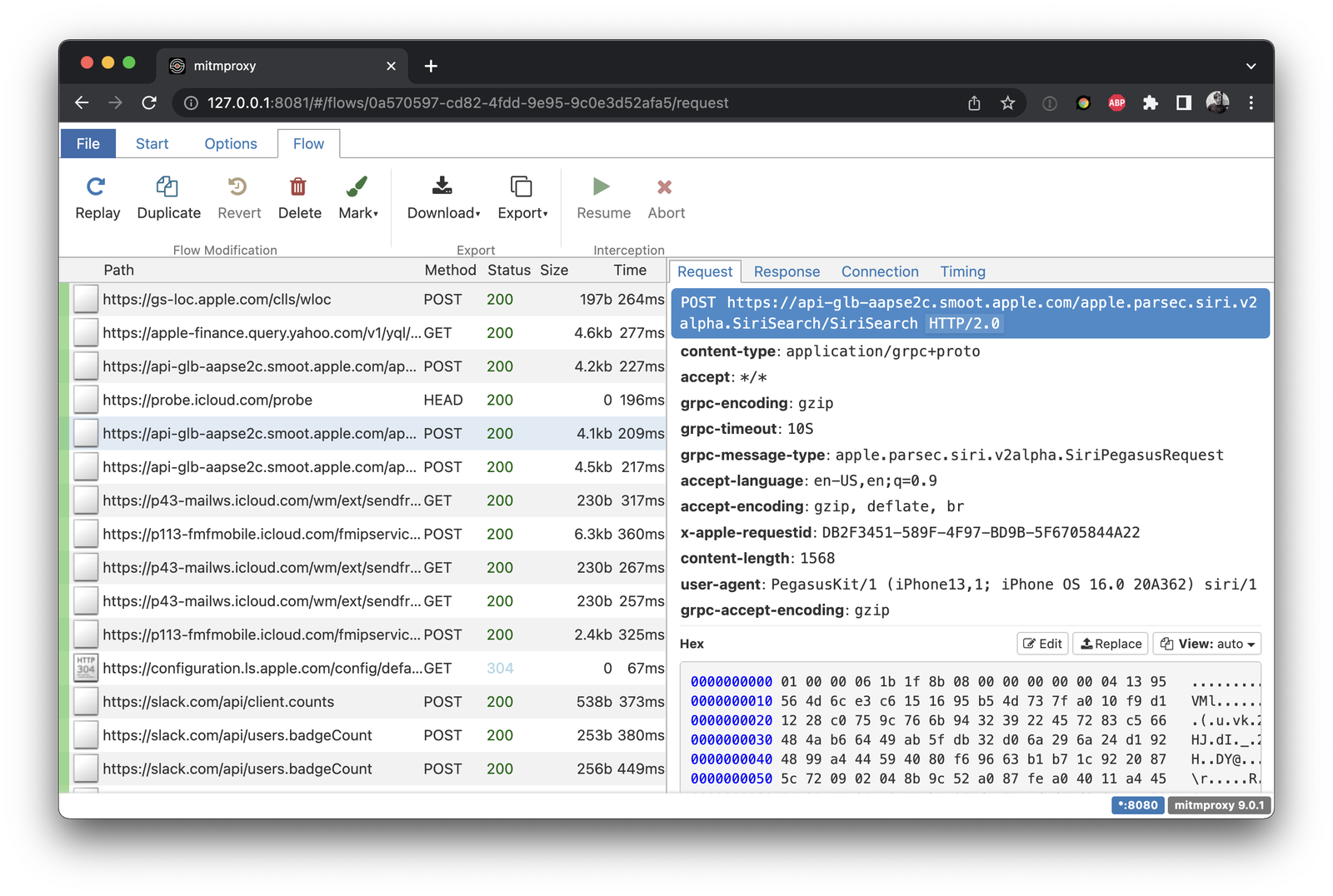
No Visible Conversation History
One of the original Siri announcement demos was reading a text message, checking for conflicting appointments, and responding to the text message. This demonstrated some contextual understanding - discussing a topic, having a sidebar, and going back to the same topic again. It was impressive because it was similar to how humans communicate. Because we have a robust context memory, we can use sentences that drop the subject, object, or verb because the meaning can still be inferred from what was said before.
On previous versions of iOS, the logical object in Siri was one of these conversations. You'd hold down the home button and Siri would take over the screen. New requests would pop to the top, but you could scroll up to reveal past requests in the same session. The new Siri removed support for these conversation flows. But the underlying logic is still there, as evidenced by requests that do reference previous context:
How's the weather in San Francisco?
How about in Oakland?
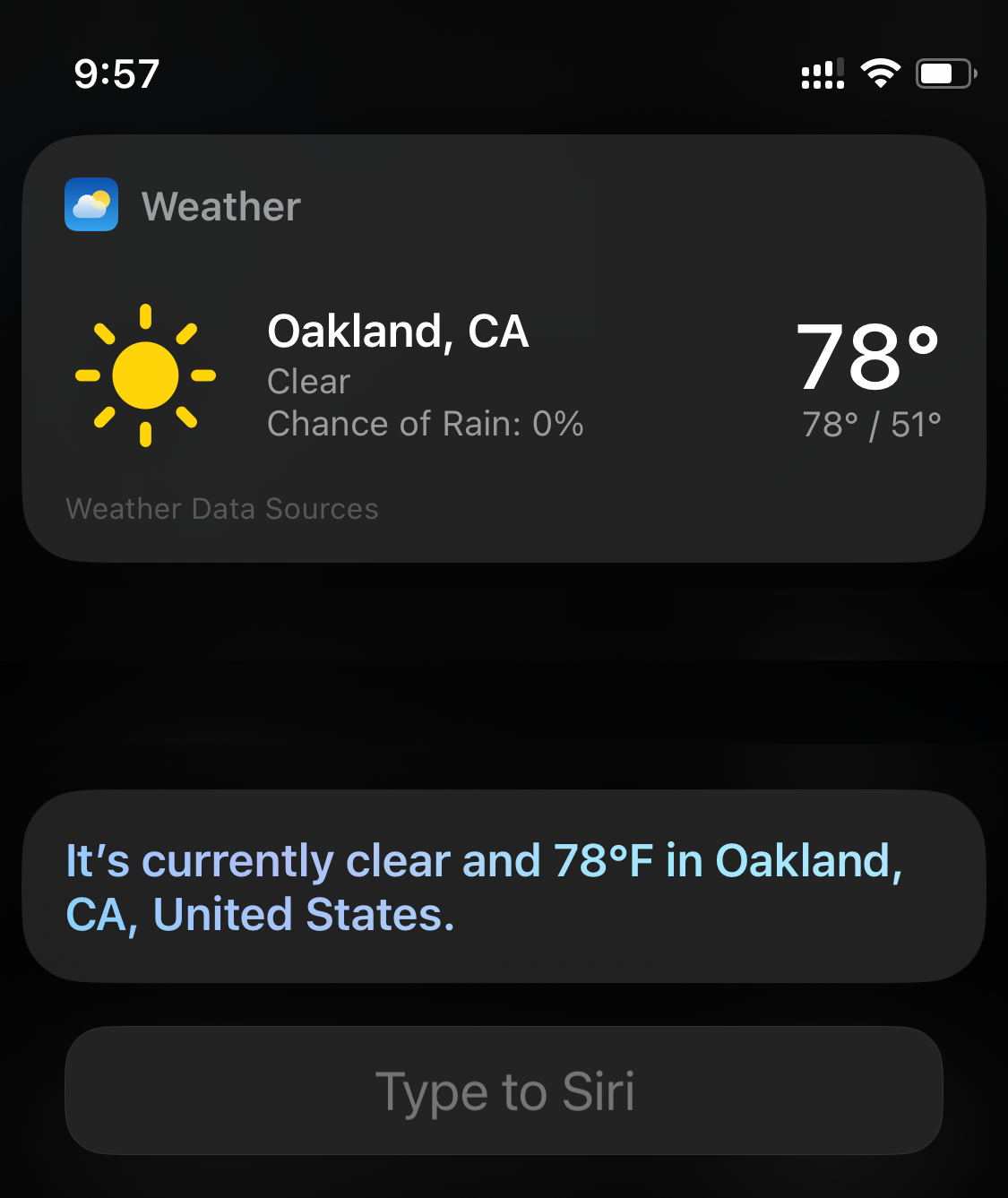
This works - it successfully knows we're asking about weather. It's just that the interface for previous prompts is hidden. The new logical object in Siri is intended to be adhoc questions.
An aside on old NLU
The previous generation of personal assistants had control logic that was largely hard-coded. They revolved around the idea of an intent - a known task that a user wanted to do like sending a message, searching for weather, etc. Detecting this intent might be keyword based or trained into a model that converts a sequence to a one-hot class space. But generally speaking there were discrete tasks and the job of the NLU pipeline was to delegate it to sub-modules. If it believes you're looking for weather, a sub-module would attempt to detect what city you're asking about. This motivated a lot of the research into NER (named entity recognition) to detect the more specific objects of interest and map them to real world quantities. city:San Francisco and city:SF to id:4467 for instance.
Conversational history was implemented by keeping track of what the user had wanted in previous steps. If a new message is missing some intent, it would assume that a previous message in the flow had a relevant intent. This process of back-detecting the relevant intent was mostly hard-coded or involved a shallow model.
With increasing device processing and neural inference, all of these models could be brought to the edge. So why not?
Motivation
I don't know the internal reason why Apple chose to roll out local Siri processing in iOS 15 - but we can loosely speculate. The first BETA was released at WWDC in June 2021, which meant that work on a local migration probably started around a year prior at June 2020. GPT-3 was released at nearly the same time: June 2020. Prior to that point generative models were still pretty niche; their main power was generating cohesive text but not logical reasoning or reliable output. The risk factor of malicious output was too high and there was no clear roadmap to decreasing the amount of hallucinations and increasing the logical abilities.
So, given this landscape, I imagine Apple had two key motivations:
-
Getting Siri on a local device would decrease latency and increase its ability to function offline.
Those are big wins for a platform that often forced users to wait longer for a server response than for users to do the task themselves. Speech-to-text and text-to-speech models were getting good enough to deploy on the edge and have fast inference to happen in realtime. And Siri's business logic itself was always a relatively simple control system, so this would be easy enough to code locally. There was no need to keep this pipeline on the server.
-
Privacy
Apple's has long tried to push more processing to the edge to avoid sending data to their servers if avoidable. Object detection in photos happens locally, encrypted iMessages are routed through a central routing system but otherwise sent directly to devices for storage, etc. Siri was a hole in this paradigm - so if Apple could push it to the edge, why wouldn't they?
Future
The new generation of self-supervised LLMs have almost nothing in common with these previous generation of NLU models. They may support task delegation through something like ChatGPT Plugins or LangChain, but their control logic and subsequent follow-ups are all the emergent property of the training data. They don't limit their universe of responses to known intents, which has shown to be incredibly powerful both for its ability to respond in natural language and its ability to bridge logic across multiple sub-systems.
Apple's in somewhat of a bind here. On one hand - they made a switch to local devices to improve offline support and improve privacy. On the other - the new generation of LLM models are drastically better than the NLU approaches of previous years. They support more functionality and better reasoning than the systems that came before.
Can't Apple just implement a new backend to Siri using LLMs? There's been a lot of movement in compressing LLMs onto laptops and phones using bit quantization. The phone POCs have focused on the 7B or 11B Alpaca models because of memory requirements (and almost certainly inference computation speeds). This is in the ballpark of the GPT3.5 model powering ChatGPT (at 20B) but a far cry away from GPT-4's 1T parameters 1.
At least until we improve model distillation and quantization we can always assume local models will be a generation behind server hosted versions. And people are perfectly willing to use server processing to access the latest and greatest models across personal and businesses2. 11B models are useful; 1T models are super useful; 5T models will probably be even more so - although with some diminishing returns to scale. Privacy might take a backseat to processing performance.
I have no doubt that Apple is working on a local generative architecture that can back future versions of Siri. I'd actually put money on them rebranding Siri in iOS 17 or iOS 18 and drop the legacy baggage. The real question in my mind is how Apple will weigh higher cognitive performance (server-side only) or more privacy (local only).
This is how I'd roadmap a feature rollout like this:
- V1. Re-introduce a server-side processing model. Speech can be converted into text on-device for speed of device->server text streaming, but the LLM processing logic should be on the server.
- V2. Allow 3rd party applications to provide a manifest with their own API contracts. Define what each API endpoint does and the data that it requires to work. If the LLM detects that these applications are relevant to the current query, route the parsed data into the application payload and send it back to the device.
- V3. Add a local model to the device that's only supported offline and routes to a server side when users have the bandwidth.
OS integration is certainly where we're headed. I'll hold my breath for WWDC this year to see if any of these dreams are realized, and what it looks like when they are.
-
At least according to Semafor. There's been some public debate about how many parameters GPT-4 actually contains. ↢
-
Quoting the linked, "ChatGPT is the fastest growing service in the history of the internet. In February 2023, it reached the 100 million user mark." ↢