Independent work: October recap
# November 5, 2022
It's been a month since going full time on my own thing. In some ways I'm surprised by how natural the transition has been. My morning standup meeting has morphed into a journaling session. My 1:1s have migrated to Discord chats about open source projects. Quarterly planning and tech designs have been replaced with my IDE. I was expecting many more moments of friction with the new lifestyle and a constant question of "What in the world are you doing?" They never really materialized.
As it is - there's just the right amount of boredom and business. I have a growing todo list but the things on it really excite me. It's been awhile since I've had the feeling where everything seems new.
Lifestyle
My days structurally look similar to how I was spending them at my last job. Just way fewer Zoom calls. I start every day with a cup of coffee, spend ten minutes writing in my journal, and then fire up my laptop. The rest of the day until evenings is spent at the keyboard, punctuated by a few walks. I always try to get out for a stroll around sunset.
I've spent a lot more time walking around, thinking, and working in the code. I have a few lingering side projects that have been taking my primary attention and I've noticed a palpable difference in outlook. A few months ago I would be fatigued after even a few hours of staring at Python. Now I've been feeling so invigorated that I can easily sit down for a 10 hour session of deep work.
We haven't stayed in one place for more than three weeks since the start of the summer. My only rig is my trusty M1 MacBook. Working exclusively on a 13" laptop is a far cry from a more formal setup, but I've been surprised at how quickly I've adapted to it. I'm still figuring out the best keyboard setup to give slightly better ergonomics but I don't mind the screen real estate too much.
GrooveProxy
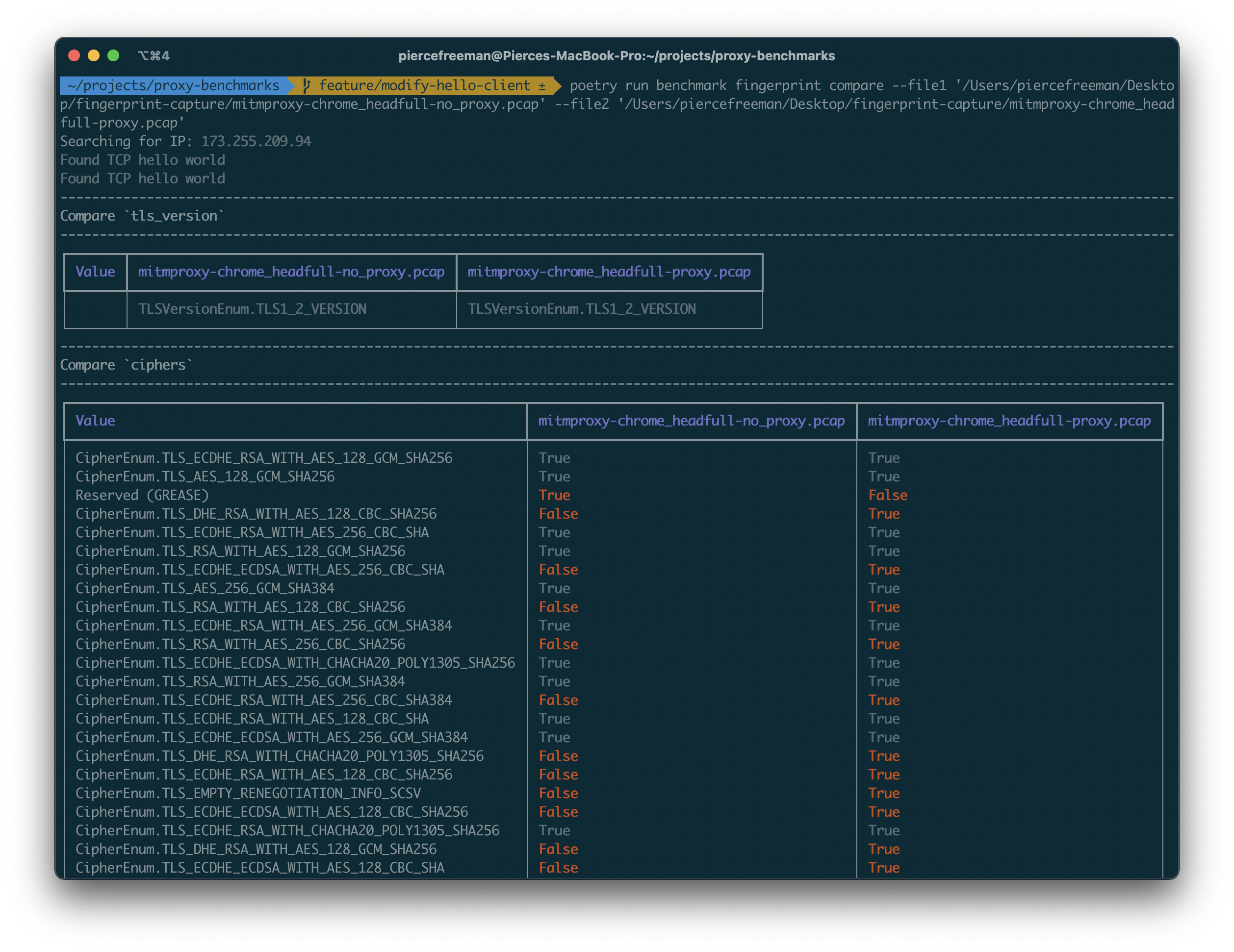
As part of some data acquisition work I've been doing I've needed browsers that efficiently browse webpages like humans do. I also want to be able to test against webpages that occur in the wild as a way to do regression testing and ensure parsing logic stays constant.
There are a few challenges to this:
- Headfull browsers are only a part of the solution. Almost all control suites (like selenium, puppeteer, playwright) inject some javascript elements into the webpage that are detectable to fingerprinting libraries. These libraries then might change website behavior.
- Most (but importantly not all) web requests pass through the chromium developer tools and are able to be intercepted. The devtools support typically lags web technology somewhat, like for service worker requests where support under certain conditions is still pending.
- Capturing all requests effectively requires a man-in-the-middle proxy server, but all of the available options use the default networking stack in their language core. Python, Node, and Golang all implement their own handshake that has unique TLS fingerprints that differ from the end browser.
I got started here by benchmarking a variety of MITM proxies and their current state of TLS fingerprints. None of them foot the bill as a crawl coordinator so I started working on GrooveProxy. It addresses the above crawl challenges with some additional support for proxy servers, request passthroughs, and request replaying. It also has Python and Node client library support.
The main sprint on it took place over two weeks during the beginning of October. It's now relatively stable. I'm in the process of deploying in the wild and addressing any bugs that crop up along the way.
Source: Github
Popdown
I was reminded when I wiped my computer at how many popups pollute the modern web even with adblockers. There are subscription prompts, paywall blocks, and GDPR notifications. I just want a clean webpage to read.
Some browser plugins exist for this problem like I don't care about cookies, which rely on a blacklist of regex and javascript patterns that eliminate common popups. But these lists are laborious to maintain and typically only apply to one specific target website. The second that a webpage changes its format or dom elements you'll start seeing the popups again.
I'm working to come up with a more generic solution here that featurizes DOM elements and predicts whether the element is part of an unnecessary popover. If so, it will remove it. Users can optionally undo this manipulation in case it was overly ambitious.
I started hacking on this during the weekends in-between work. I haven't made as much progress since going independent as I would have liked. Data collection is proving the main friction, as well as Groove taking more of my attention. I still have to aggregate a list of websites with popups or removable paywalls and add this to an index. But I have some prototypes of featurization so I think the ML stage will be relatively straightforward.
Source: Github
Next month
November has already kicked off. With it comes a bit more traveling where I can further stress-test this setup.
I've spent the last few days working on a new background processing computational graph library dagorama. Hoping to get this stable and wrapped up within the next week. Then turning towards some core business challenges.